






Google DeeMind introduced RoboCat, a self-improving AI agent for robotics, in its latest paper. RoboCat can learn to perform a variety of tasks across different robotic arms and then self-generate new training data to better improve its technique.
Typically, robots are programmed to perform one specific task or a few tasks well, but recent advances in AI are opening doors to robots being able to learn a variety of tasks.
Google has previously done research exploring how to develop robots that can learn to multitask at scale and how to combine the understanding of language models with the real-world capabilities of a helper robot. But RoboCat aims to go beyond these capabilities. This latest AI agent aims to solve and adapt to multiple tasks and do so across different, real robots.
Google said RoboCat can pick up a new task with as few as 100 demonstrations because it draws from a large and diverse dataset. The agent is based on Google’s multimodal model Gato (Spanish for “cat”), which processes language, images, and actions in both simulated and physical environments.
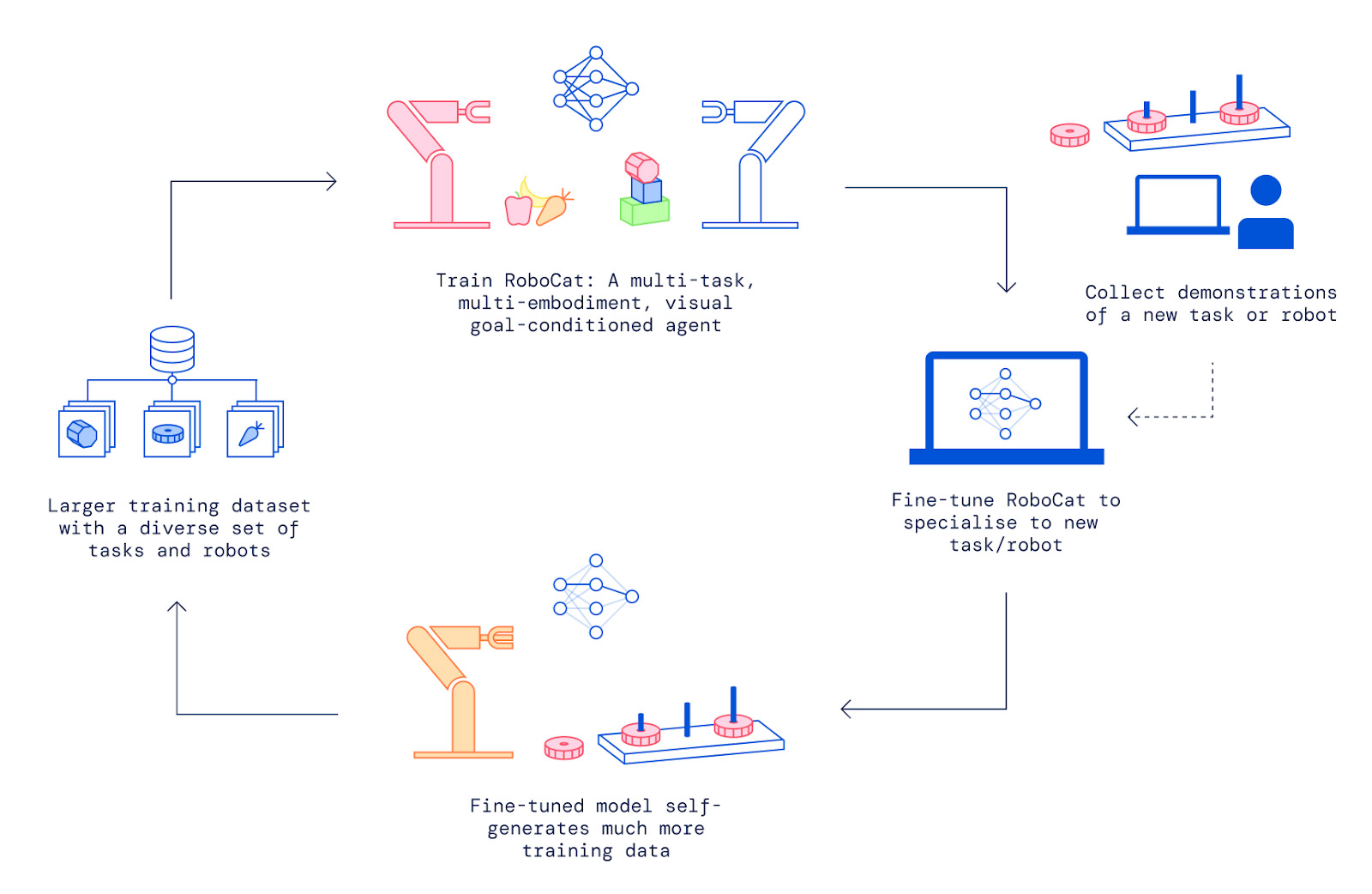
DeepMind researchers combined Gato’s architecture with a large training dataset of sequences of images and actions from various robot arms, solving hundreds of different tasks. To learn tasks, RoboCat would do a round of training, and then be launched into a “self-improvement” training cycle with a set of previously unseen tasks.
RoboCat learned each new task by following five steps:
- First, the research team would collect anywhere from 100 to 1,000 demonstrations of a new task using a robotic arm controlled by a human.
- The researchers would fine-tune RoboCat on this new task and arm, creating a specialized spin-off agent.
- The spin-off agent then practices this new task an average of 10,000 times, generating more training data for RoboCat.
- The system incorporates the original data and self-generated data into RoboCat’s existing training dataset.
- The team trains a new version of RoboCat on the new training dataset.
An illustration of RoboCat’s training cycle. | Source: Google DeepMind
All of this training results in the latest RoboCat having millions of trajectories, from both real and simulated arms, to learn from. Google used four different types of robots and many different robotic arms to collect vision-based data representing the tasks RoboCat could be trained to perform.
This large and diverse training means that RoboCat learned to operate different robotic arms within just a few hours. It was also able to extend these skills to new tasks quickly. For example, while RoboCat had been trained on arms with two-pronged grippers, it was able to adapt to a more complex arm with a three-fingered gripper and twice as many controllable inputs.
After observing 1,000 human-controlled demonstrations, which took just hours to collect, RoboCat could direct this arm with a three-pronged gripper dexterously enough to pick up gears successfully 86% of the time.
With the same number of demonstrations, RoboCat could also adapt to solve tasks that combine precision and understanding, like removing a specific fruit from a bowl and solving a shape-matching puzzle.
RoboCat only gets better at adding additional tasks the more tasks it learns. The first version of RoboCat that DeepMind created was only able to complete previously unseen tasks 36% of the time after learning from 500 demonstrations per task. While the final version of RoboCat discussed in the paper more than doubled this success rate.






